CSpell Profiling Analysis
I. Introduction
Each questions (471) in the training set were tested and recorded the elapsed time. These profiling information was analyzed for optimizing the software program performance.
II. Processes
Test on non-word only in the training set:
- Step 1: non-word option:
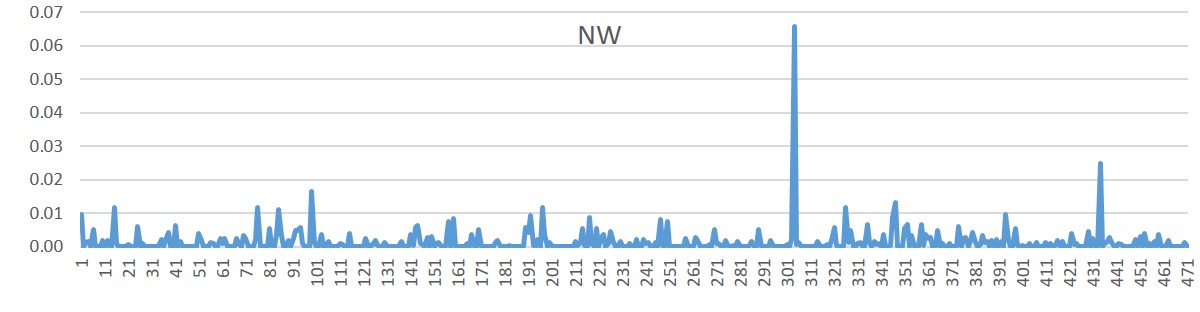
- The X-axis is the questions used in the training set
- The Y-axis is the elapsed time of CSpell correction for each question
- Two peaks, happen when errors has long length. Due to the candidate generating algorithm (reversed edit distance), these long length creates too many permutation and result in long elapsed time.
| ID | file name | longest error token
|
|---|
| 304 | 16859.txt | gastreonterology-colonoscopy
|
| 434 | 66.txt | backwith-Wieddeman
|
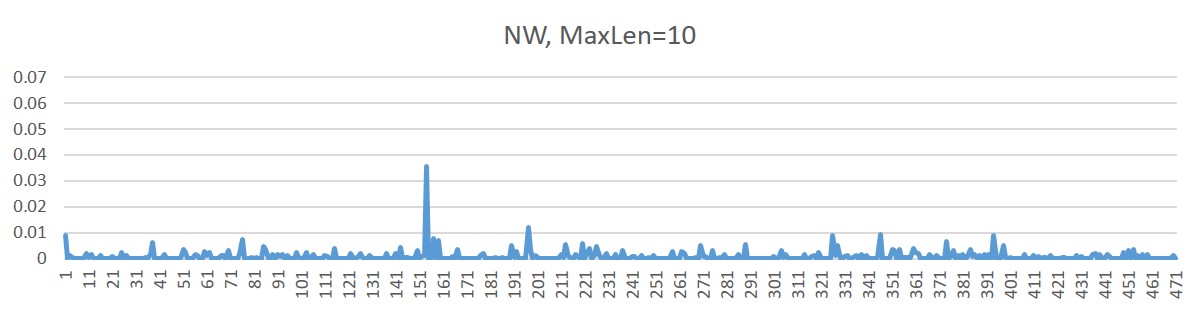
- Step 2: set the max. length of spelling error to 10
- To fix the above issue, we set the max-length of error to 10 (configurable)
- One peak, happen when possible splits is big.
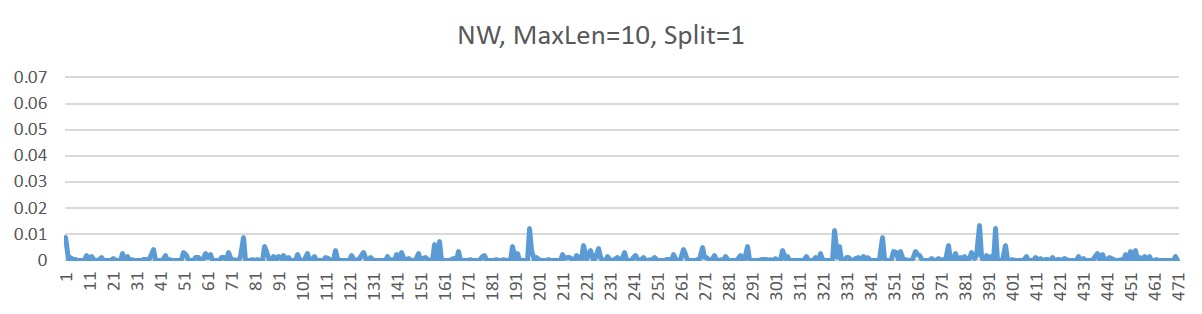
- Step 3: set the max. split to 1
- To fix the above issue, we set the max split to 1 (configurable)
- No obvious peak found
III. Conclusion
All peaks are expected and the empirical best values are set in the default configuration file of CSpell for the best performance.