LMW Candidate Post-Processes Overview
I. Objectives:
This page describes the design concept of the post-processes on LMW candidate post-processing. The post-processes are conducted when:
- To calcualte the performance candidate files: executed when a LMW candidate file is competed.
- To retrieve invalid LMWs: during the Lexicon annual release processes.
II. Design:
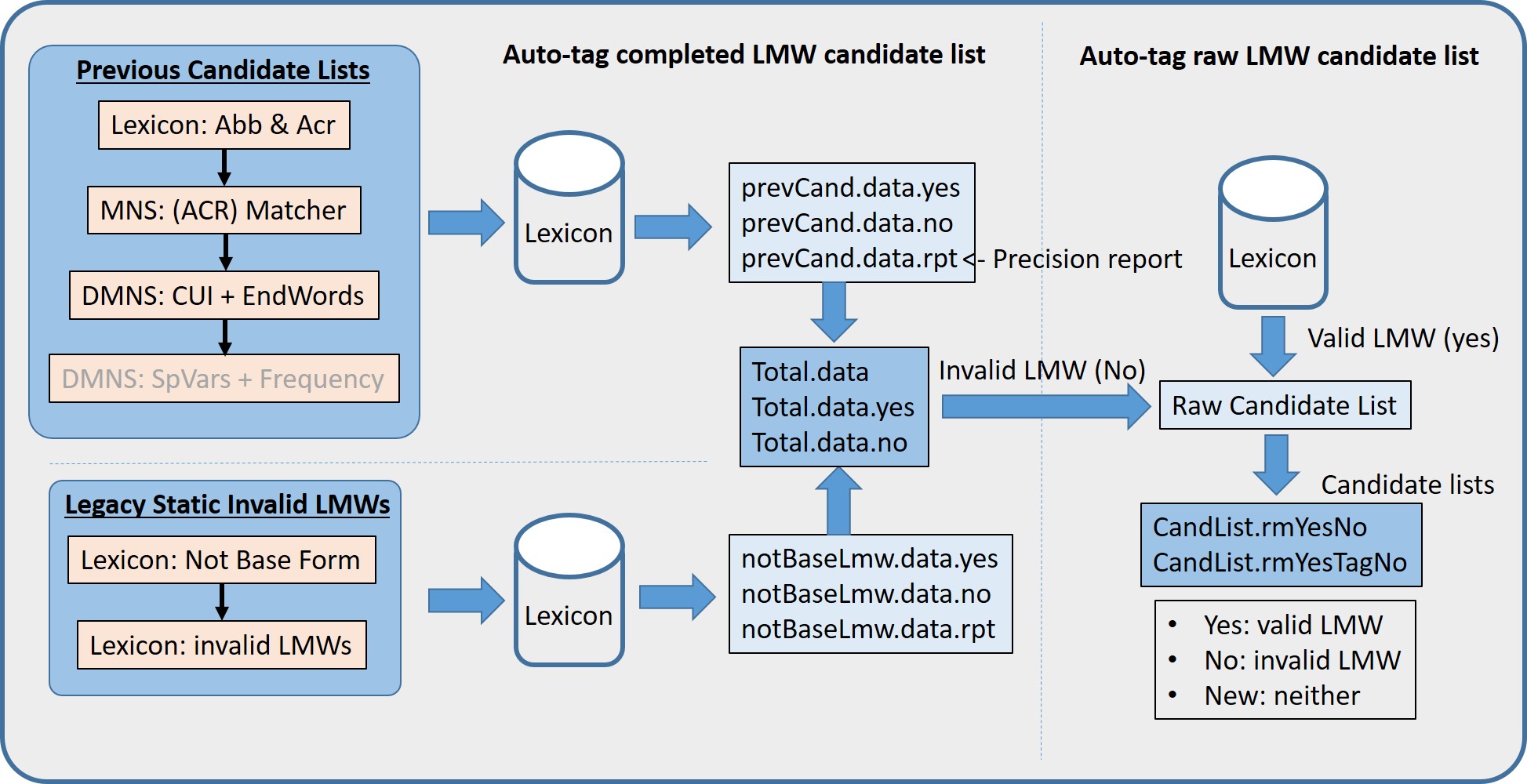
The design concept is shown in the shcematic diagram below. They are summaried as folows:
- No tags [Y|N] are needed on candidate files.
- Use the latest Lexicon to auto-tag valid and invalid words from a completed candidate list to decide the performance on precision
- Theoretically, all valid words are in the Lexicon. That is valid LMWs are identified if they are inflectional variants from the latest Lexicon.
- Candidates are not in the Lexicon are invalid words.
- Invlaid LMWs includes two sources:
- From previous candidate files while they are not in the Lexicon (prevcand.data.no)
- From known (legacy) invalid base forms (notBaseLmw.data.no)
- Use those invalid word to update invalid base/LMW files
- Use the Invlaid base/LMW file to auto-tag [AUTO_NO] on a raw generated LMW candidates before sent to linguists.
III. Algorithm Details:
After 2018+, a systematic post-process was implemented to filtered valid and invalid LMW from candidate list:
- use the latest Lexicon to tag valid|invalid LMWs
- Valid LMWs:
- Collect all terms from the latest Lexicon (inflVars). These are valid LMWs.
- Generate inflVars from LexBuild - postPorcess
- Invalid LMWs:
- Get all terms from previous candidate list (without |ATUO_N tag)
- Remove valid LMWs from above
- The rest are invalid LMWs
- Tag invalid LMWs from the new candidate list as [AUTO_N]
=>These can be removed if all of them are [n] after several running through several candidate list.
- Auto-tag raw LMW candidate list before sent to Linguists
- The generated raw candidate lists are auto-tagged using post-processes (00.CandidateList, step 10) to auto-tag:
- valid LMWs (terms in the latest Lexicon inflVars.data)
- invalid LMWs (known invalid LMWs, Total.data.no)
- CandList.rmYesNo are new terms are not auto-tagged. They are used as candidate list (to calculate precision), as shown at the end of the process in the above diagram.
- CandList.rmYesTagNo is the actual file sent to linguists so they can have another chance to review terms with AUTO_TAG_NO to ensure they are invalid LMWs.
- The precision of all models for the latest Lexicon are in the prevCand.data.rpt.
- Auto-tag completed LMW candidate list
- Once candidate list are completed (submitted and approved) by the linguists, the list need to go through processes in 00.CandidateList (step 1-3) to update invalid LMWs (prevCand.data.no)
- Add completed candidate list to appropriated directory (${LMW_DIR}/data/Candidates/..)
- Run 00.CandidateList step 1.
- candidates are in the linked latest inflVars.data are valid LMWs (prevCand.data.yes)
- candidates are not in the latest inflVars.data are invalid LMWs (prevCand.data.no)
- Invalid LMWs in the candidate list are automatic updated, prevCand.data.no in the above diagram
- All skipped candidates are considered as invalid LMWs in this process (that is why the program provides a 2nd chance for linguist to review invalid LMWs - ATUO_TAG_NO in the final tagging process .
- CandList.rmYesNo should become empty by runing through the above process with latest Lexicon and invalid LMWs when it is completed.
- Valid candidates is added to the Lexicon throguh LexBuild DB.
- Invalid candidates is added to the invalid LMWs file.
- Other invalid terms (notBaseLmw.data.no) are static legacy data used before 2019-. (no update after 2020+)
- The file Total.data.no (= prevCand.data.no + notBaseLmw.data.no) are used as the latest invalid LMW collections. This file should be used in LexAccess.Files after 2020+.
IV. Processes before 2018- (not used anymore)
The process used before 2018- are described below for reference purpose.